Milvus 构建在 Faiss、HNSW、DiskANN、SCANN 等流行的向量搜索库之上,专为在包含数百万、数十亿甚至数万亿向量的密集向量数据集上进行相似性搜索而设计。在继续之前,请先熟悉一下 Embeddings 检索的基本原理。
Milvus 还支持数据分片、流式数据摄取、动态 Schema、结合向量和标量数据的搜索、多向量和混合搜索、稀疏向量和其他许多高级功能。该平台可按需提供性能,并可进行优化,以适应任何嵌入式检索场景。我们建议使用 Kubernetes 部署 Milvus,以获得最佳的可用性和弹性。
Milvus 采用共享存储架构,其计算节点具有存储和计算分解及横向扩展能力。按照数据平面和控制平面分解的原则,Milvus 由四层组成:访问层、协调器服务、工作节点和存储。这些层在扩展或灾难恢复时相互独立。
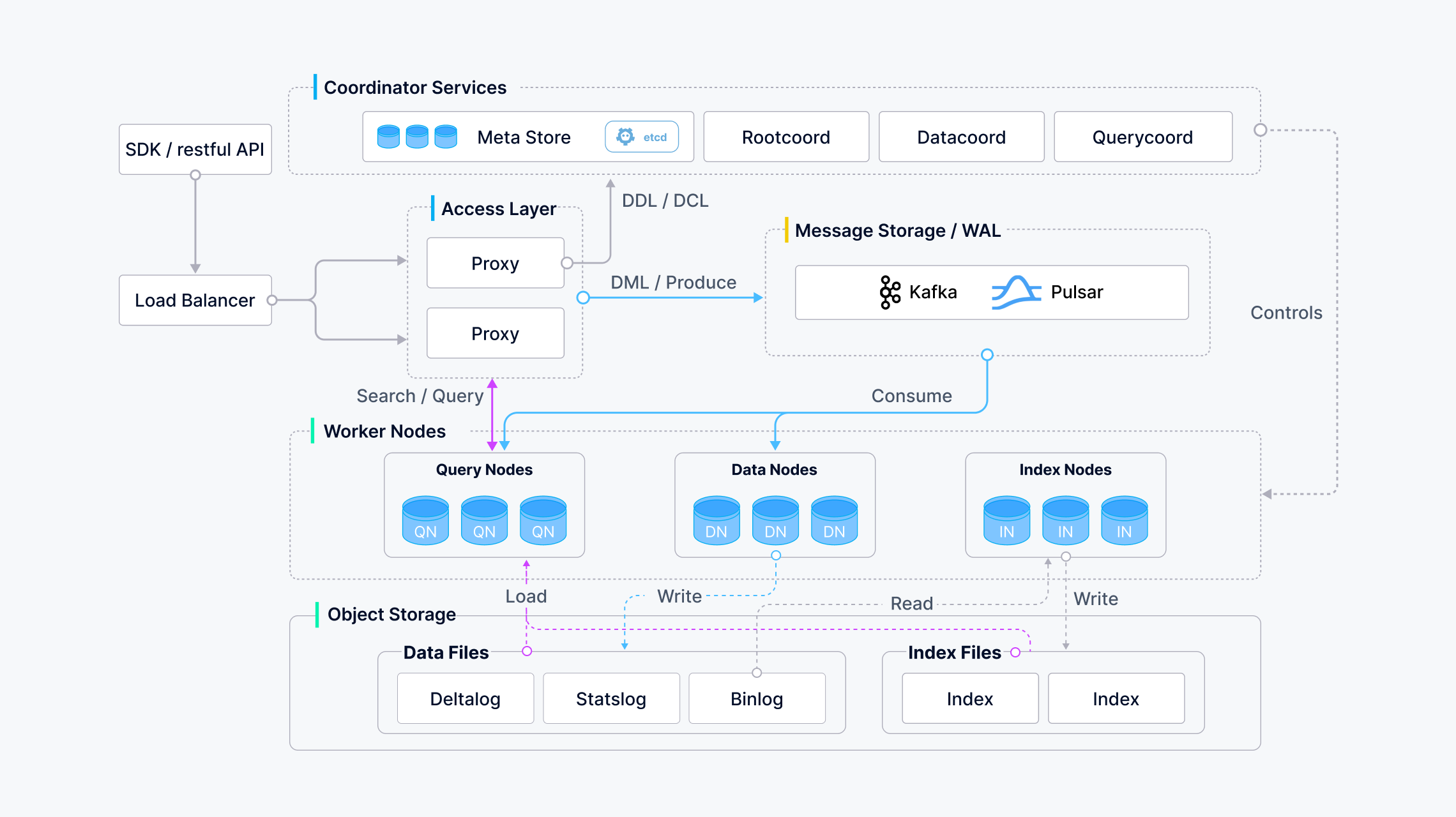 架构图
架构图
根据该图,接口可分为以下几类:
DDL / DCL:createCollection / createPartition / dropCollection / dropPartition / hasCollection / hasPartition
DML / Produce:插入 / 删除 / 上移
DQL:搜索/查询
主要组件
Milvus 有两种运行模式:独立运行和集群运行。这两种模式具有相同的功能。你可以选择最适合你的数据集大小、流量数据等的模式。目前,Milvus 单机版还不能 "在线 "升级到 Milvus 集群。
Milvus 单机版
Milvus 单机版包括三个组件:
Milvus:核心功能组件。
元数据存储:元数据引擎,用于访问和存储 Milvus 内部组件(包括代理、索引节点等)的元数据。
对象存储:存储引擎,负责 Milvus 的数据持久化。
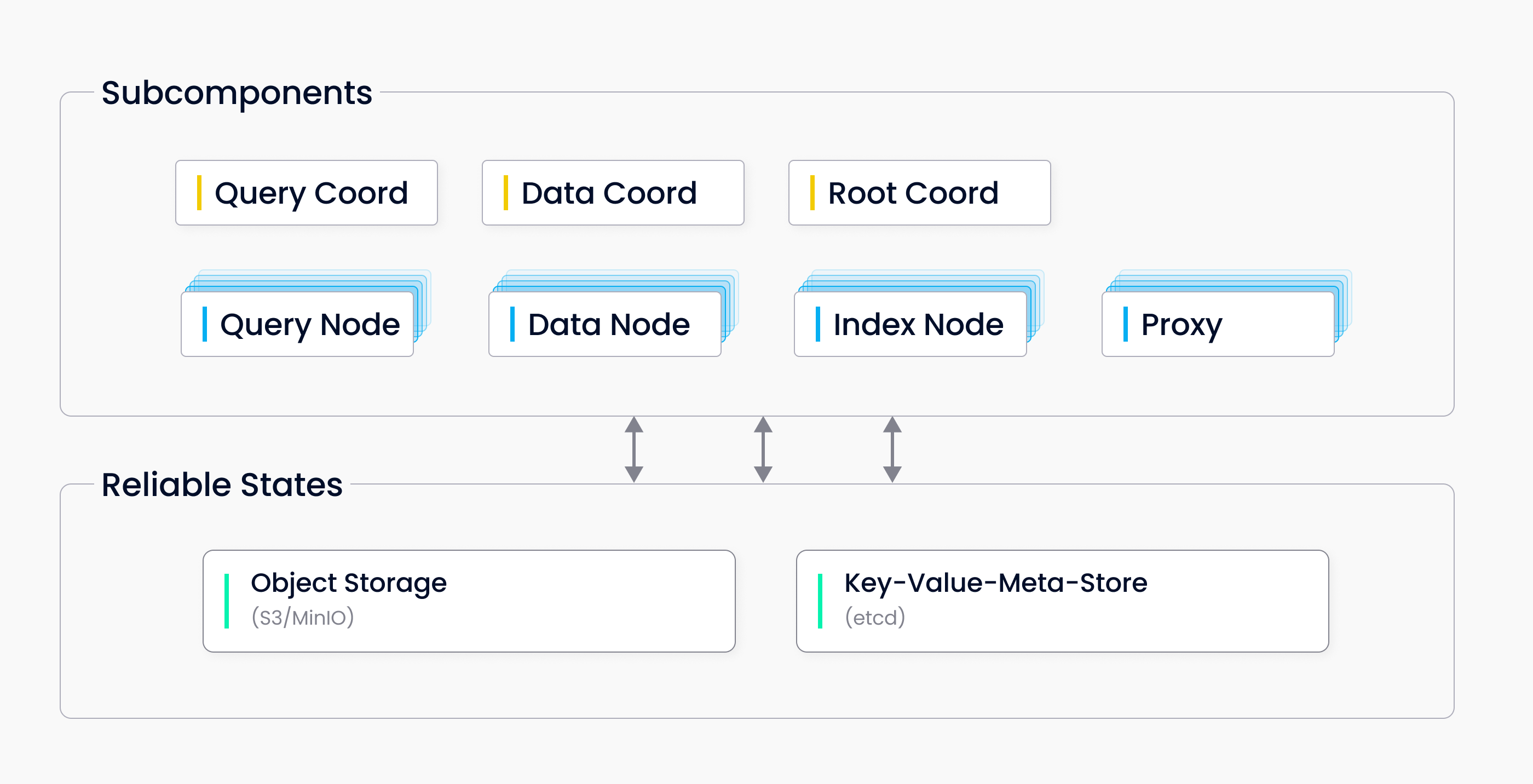 独立架构
独立架构
Milvus 集群
Milvus 集群包括七个微服务组件和三个第三方依赖项。所有微服务都可以独立部署在 Kubernetes 上。
微服务组件
根节点
代理
查询坐标
查询节点
数据节点
索引节点
数据节点
第三方依赖
元存储:存储集群中各种组件的元数据,如 etcd。
对象存储: 负责集群中索引和二进制日志文件等大型文件的数据持久化,如 S3
日志代理:管理最近突变操作的日志,输出流式日志,并提供日志发布-订阅服务,如 Pulsar。
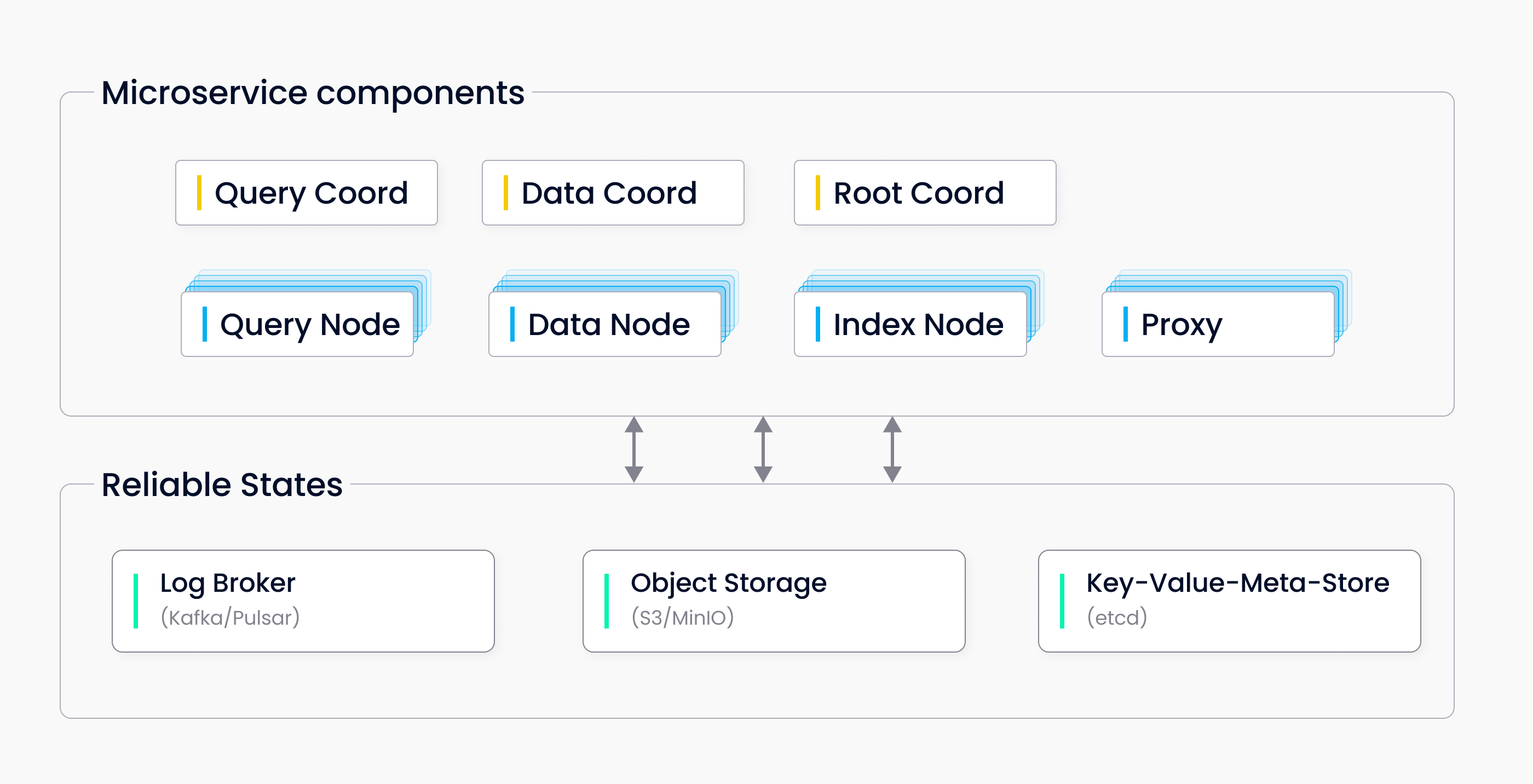 分布式架构
分布式架构
存储/计算分解
按照数据平面和控制平面分解的原则,Milvus 包括四个层,在可扩展性和灾难恢复方面相互独立。
接入层
访问层由一组无状态代理组成,是系统的前端层,也是用户的终端。它验证客户端请求并减少返回结果:
代理本身是无状态的。它使用 Nginx、Kubernetes Ingress、NodePort 和 LVS 等负载均衡组件提供统一的服务地址。
由于 Milvus 采用的是大规模并行处理(MPP)架构,代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端。
协调服务
协调器服务将任务分配给工作节点,起到系统大脑的作用。它承担的任务包括集群拓扑管理、负载平衡、时间戳生成、数据声明和数据管理。
协调器有三种类型:根协调器(root coordinator)、数据协调器(data coordinator)和查询协调器(query coordinator)。
根协调器(根协调器)
根协调器处理数据定义语言(DDL)和数据控制语言(DCL)请求,如创建或删除 Collections、分区或索引,以及管理 TSO(时间戳 Oracle)和时间刻度签发。
查询协调器(查询协调器)
查询协调器负责管理查询节点的拓扑结构和负载平衡,以及从增长网段到封存网段的切换。
数据协调器(数据协调器)
数据协调器管理数据节点和索引节点的拓扑结构,维护元数据,并触发刷新、压缩和索引构建以及其他后台数据操作。
工作节点
手臂和腿。工作节点是哑执行器,它们遵从协调器服务的指令,执行来自代理的数据操作语言(DML)命令。由于存储和计算分离,工作节点是无状态的,部署在 Kubernetes 上时可促进系统扩展和灾难恢复。工作节点有三种类型:
查询节点
查询节点通过订阅日志代理检索增量日志数据并将其转化为不断增长的片段,从对象存储中加载历史数据,并在向量和标量数据之间运行混合搜索。
数据节点
数据节点通过订阅日志代理检索增量日志数据,处理突变请求,将日志数据打包成日志快照并存储在对象存储中。
索引节点
索引节点构建索引。 索引节点不需要常驻内存,可以使用无服务器框架来实现。
存储
存储是系统的骨骼,负责数据持久性。它包括元存储、日志代理和对象存储。
元存储
元存储存储元数据的快照,如 Collections Schema 和消息消耗检查点。元数据的存储要求极高的可用性、强一致性和事务支持,因此 Milvus 选择 etcd 作为元存储。Milvus 还使用 etcd 进行服务注册和健康检查。
对象存储
对象存储用于存储日志快照文件、标量和向量数据的索引文件以及中间查询结果。Milvus 使用 MinIO 作为对象存储,可随时部署在 AWS S3 和 Azure Blob 这两个全球最流行、最具成本效益的存储服务上。然而,对象存储的访问延迟较高,并按查询次数收费。为了提高性能并降低成本,Milvus 计划在基于内存或固态硬盘的缓存池上实现冷热数据分离。
日志代理
日志代理是一个支持回放的发布子系统。它负责流数据持久化和事件通知。当工作节点从系统故障中恢复时,它还能确保增量数据的完整性。Milvus 集群使用 Pulsar 作为日志代理;Milvus 单机使用 RocksDB 作为日志代理。此外,日志代理可以随时替换为 Kafka 等流式数据存储平台。
Milvus 围绕日志代理构建,遵循 "日志即数据 "原则,因此 Milvus 不维护物理表,而是通过日志持久化和快照日志来保证数据的可靠性。
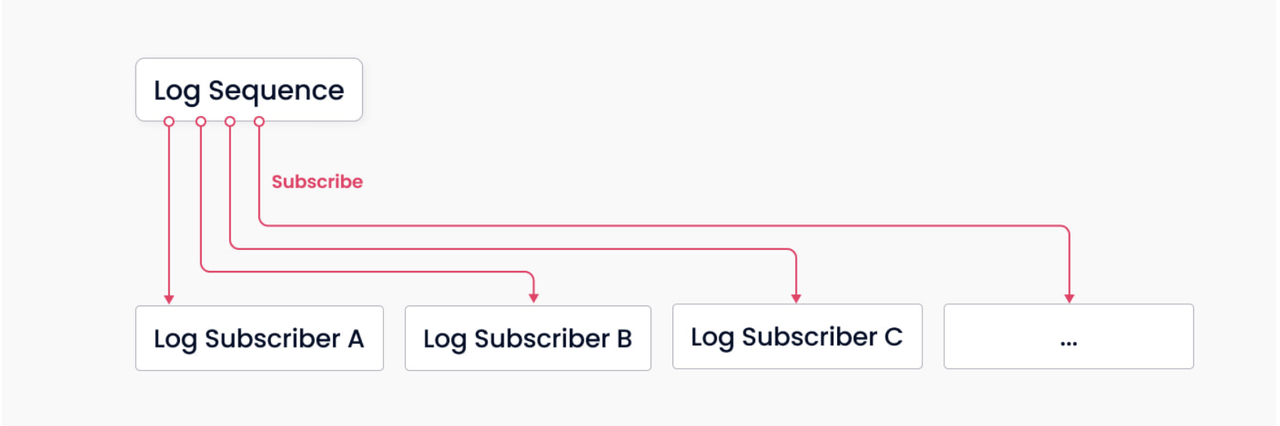 日志机制
日志机制
日志代理是 Milvus 的支柱。它负责数据持久性和读写分解,这要归功于其与生俱来的发布-子机制。上图是对该机制的简化描述,其中系统分为两个角色:日志代理(负责维护日志序列)和日志订阅者。前者记录所有改变 Collections 状态的操作;后者订阅日志序列以更新本地数据,并以只读副本的形式提供服务。在变更数据捕获(CDC)和全局分布式部署方面,pub-sub 机制也为系统的可扩展性留出了空间。
数据插入
您可以为 Milvus 中的每个 Collections 指定若干分片,每个分片对应一个虚拟通道(vchannel)。如下图所示,Milvus 会为日志代理中的每个 vchannel 分配一个物理通道(pchannel)。任何传入的插入/删除请求都会根据主键的哈希值路由到分片。
由于 Milvus 没有复杂的事务,因此 DML 请求的验证工作被前移到代理。代理会向 TSO(Timestamp Oracle)请求每个插入/删除请求的时间戳,TSO 是与根协调器共用的计时模块。由于旧的时间戳会被新的时间戳覆盖,因此时间戳可用于确定正在处理的数据请求的顺序。代理从数据协调器分批检索信息,包括实体的分段和主键,以提高总体吞吐量,避免中央节点负担过重。
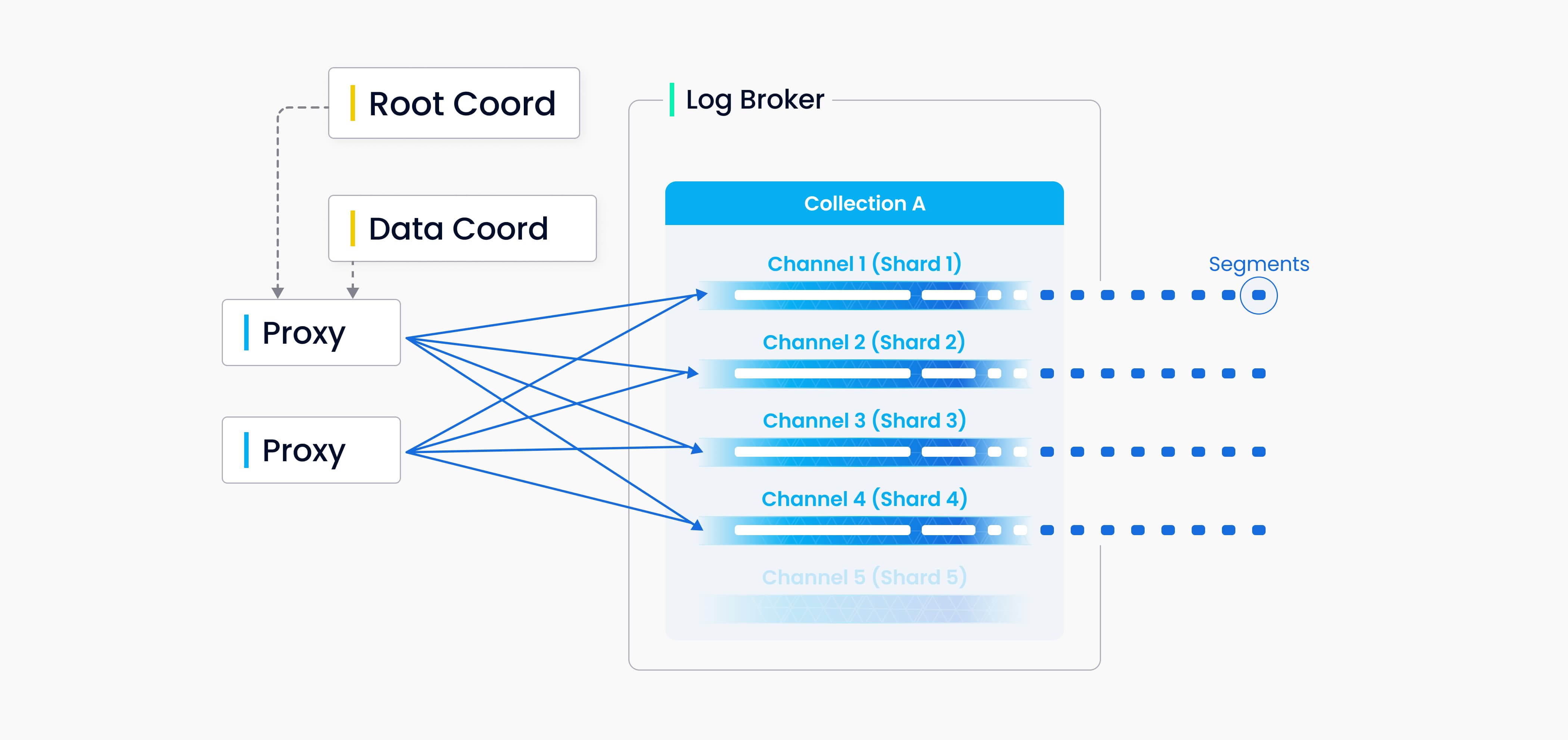 通道 1
通道 1
DML(数据操作符)操作和 DDL(数据定义语言)操作都会写入日志序列,但 DDL 操作由于出现频率较低,因此只分配一个通道。
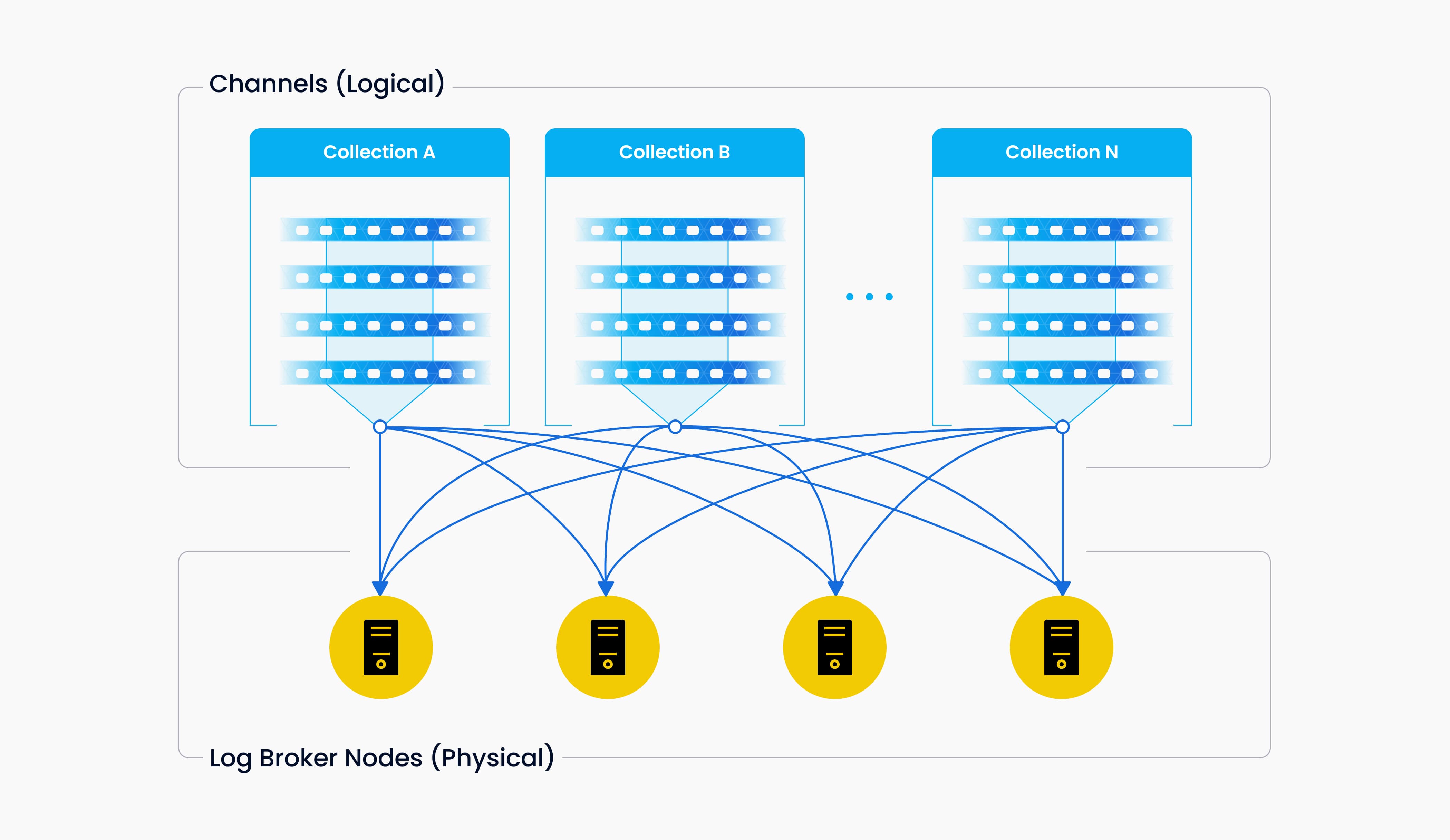 通道 2
通道 2
V 通道保存在底层日志代理节点中。每个通道在物理上不可分割,可用于任何一个节点,但只能用于一个节点。当数据摄取率达到瓶颈时,要考虑两个问题:日志代理节点是否超载并需要扩展,以及是否有足够的分片来确保每个节点的负载平衡。
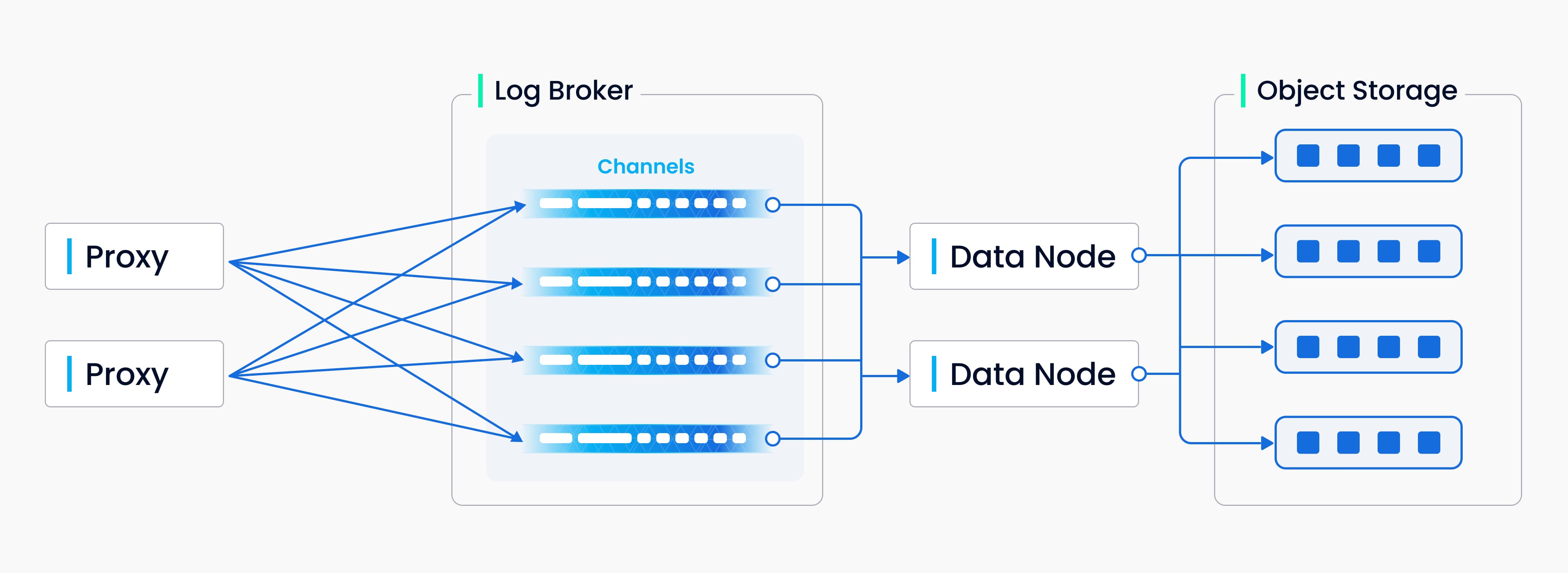 写日志顺序
写日志顺序
上图封装了写入日志序列过程中涉及的四个组件:代理、日志代理、数据节点和对象存储。该流程涉及四项任务:验证 DML 请求、发布-订阅日志序列、从流日志转换为日志快照,以及持久化日志快照。这四项任务相互解耦,以确保每项任务都由相应的节点类型来处理。同一类型的节点是平等的,可以灵活、独立地扩展,以适应各种数据负载,尤其是海量、高波动的流数据。
索引构建
索引建立由索引节点执行。为避免数据更新时频繁建立索引,Milvus 将一个 Collections 进一步划分为多个分段,每个分段都有自己的索引。
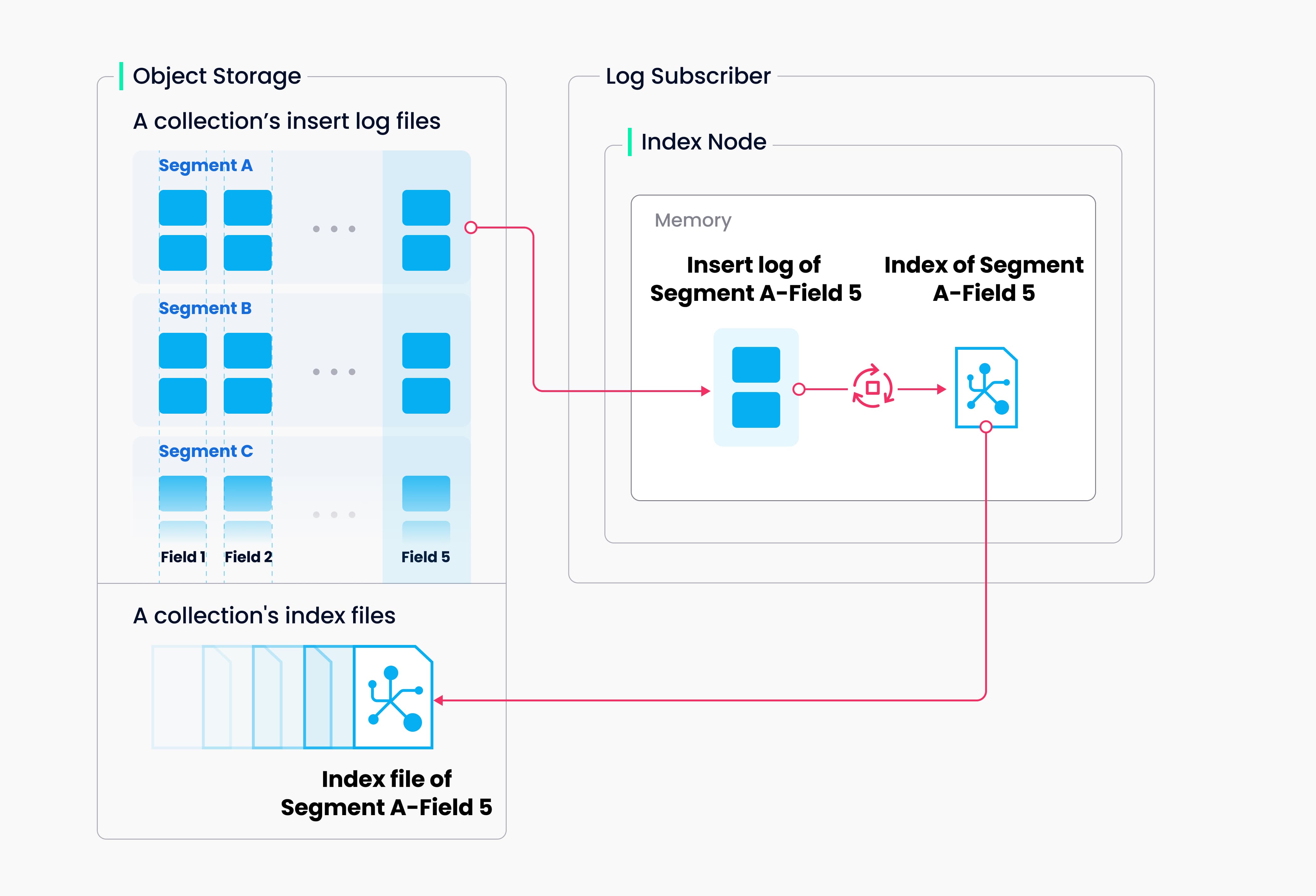 建立索引
建立索引
Milvus 支持为每个向量场、标量场和主场建立索引。索引构建的输入和输出都与对象存储有关:索引节点将需要索引的日志快照从段(位于对象存储中)加载到内存,反序列化相应的数据和元数据以建立索引,索引建立完成后序列化索引,并将其写回对象存储。
索引构建主要涉及向量和矩阵操作,因此是计算和内存密集型操作。向量由于其高维特性,无法用传统的树形索引高效地建立索引,但可以用这方面比较成熟的技术建立索引,如基于集群或图形的索引。无论其类型如何,建立索引都涉及大规模向量的大量迭代计算,如 Kmeans 或图遍历。
与标量数据索引不同,建立向量索引必须充分利用 SIMD(单指令、多数据)加速。Milvus 天生支持 SIMD 指令集,例如 SSE、AVX2 和 AVX512。考虑到向量索引构建的 "打嗝 "和资源密集性质,弹性对 Milvus 的经济性而言变得至关重要。Milvus 未来的版本将进一步探索异构计算和无服务器计算,以降低相关成本。
此外,Milvus 还支持标量过滤和主字段查询。为了提高查询效率,Milvus 还内置了布鲁姆过滤索引、哈希索引、树型索引和反转索引等索引,并计划引入更多外部索引,如位图索引和粗糙索引。
数据查询
数据查询指的是在指定的 Collections 中搜索与目标向量最接近的k个向量,或搜索与向量在指定距离范围内的所有向量。向量会连同其相应的主键和字段一起返回。
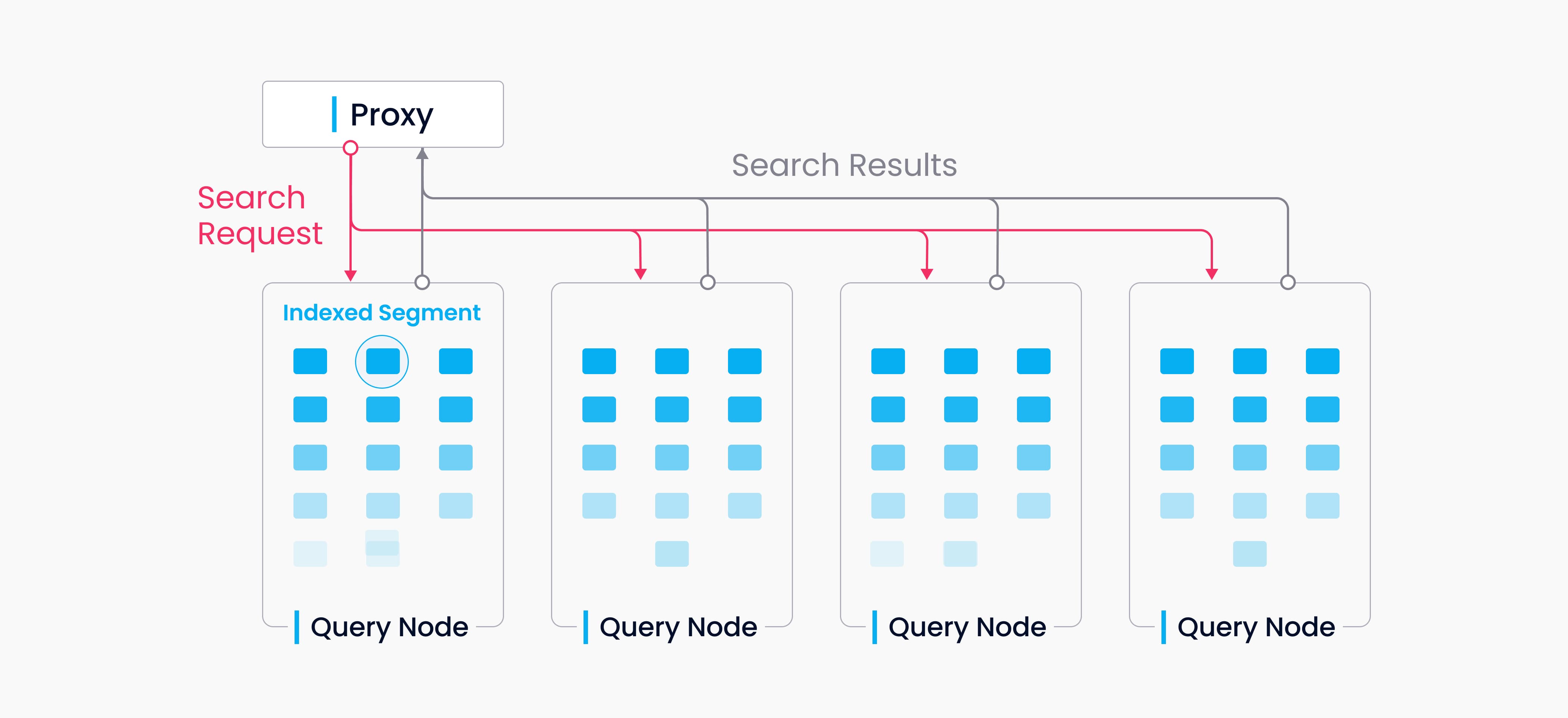 数据查询
数据查询
Milvus 中的 Collections 分成多个分段,查询节点按分段加载索引。当搜索请求到达时,它会广播给所有查询节点进行并发搜索。然后,每个节点修剪本地段,搜索符合条件的向量,并还原和返回搜索结果。
在数据查询中,查询节点是相互独立的。每个节点只负责两项任务:根据查询协调器的指令加载或释放段;在本地段内进行搜索。代理负责减少每个查询节点的搜索结果,并将最终结果返回给客户端。
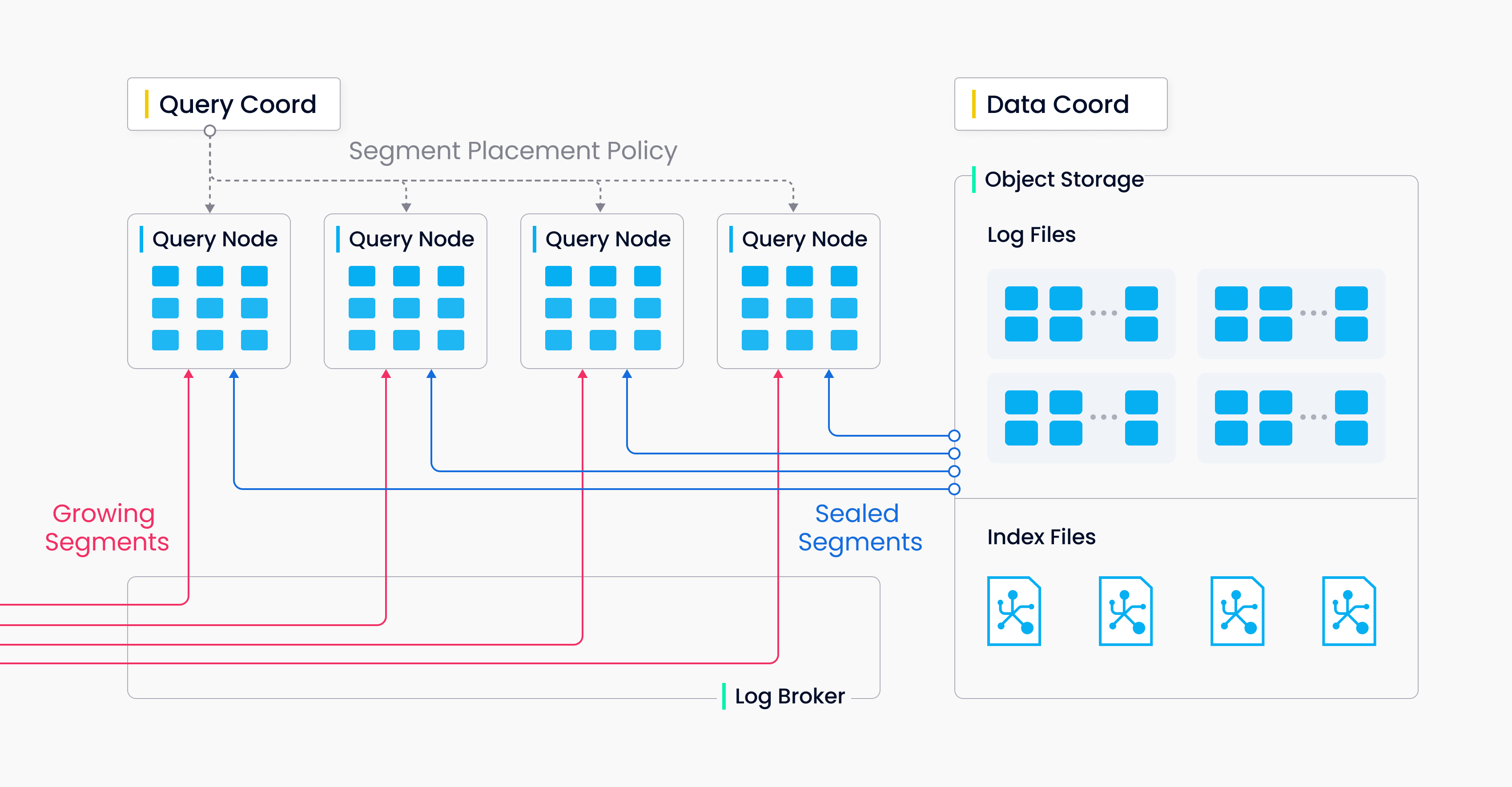 分段
分段
分段有两种,一种是增长分段(用于增量数据),另一种是封存分段(用于历史数据)。查询节点向 vchannel 订阅最新更新(增量数据),作为增长段。当增长数据段达到预定义阈值时,数据协调器就会将其封存,并开始建立索引。然后,由查询协调器启动移交操作符,将增量数据转为历史数据。查询协调器将根据内存使用情况、CPU 开销和段落数量,在所有查询节点之间平均分配封存的段落。
Knowhere
Knowhere 是 Milvus 的核心向量执行引擎,它集成了多个向量相似性搜索库,包括Faiss、Hnswlib和Annoy。Knowhere 的设计还支持异构计算。它可以控制在哪个硬件(CPU 或 GPU)上执行索引构建和搜索请求。这就是Knowhere名字的由来--知道在哪里执行操作符。未来的版本将支持更多类型的硬件,包括 DPU 和 TPU。
Milvus架构中的Knowhere
下图说明了 Knowhere 在 Milvus 架构中的位置。
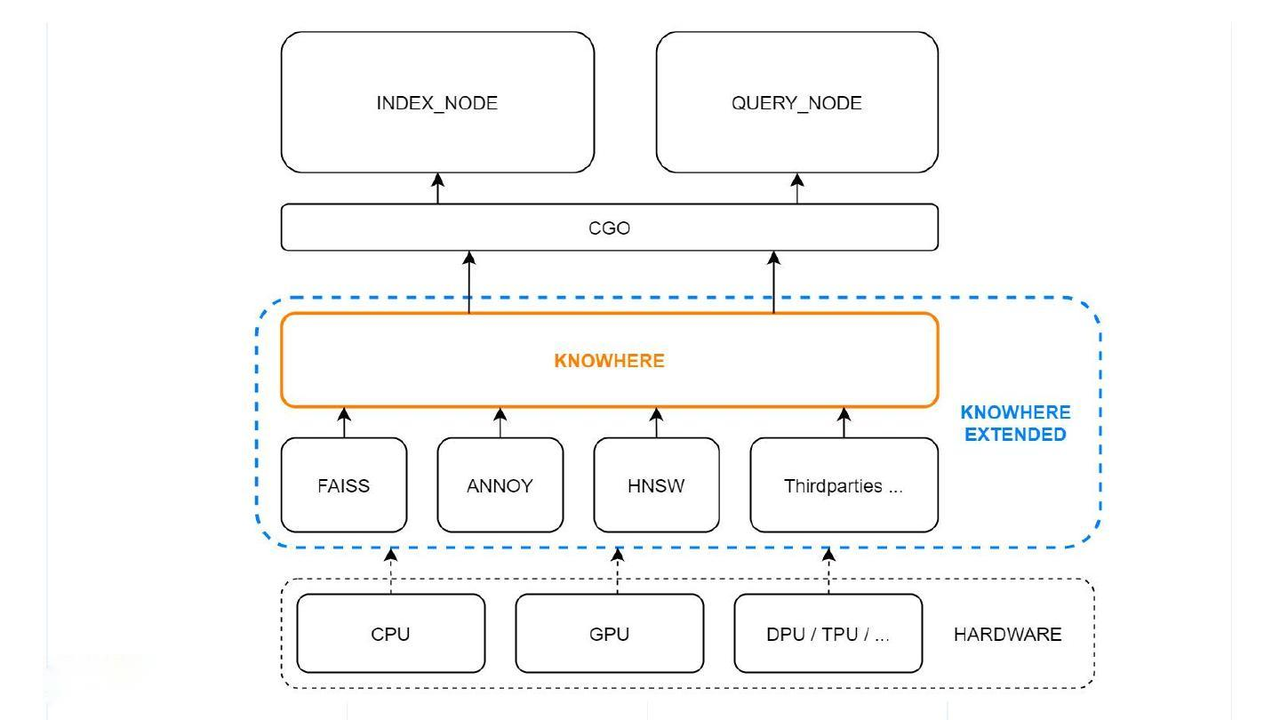 Knowhere
Knowhere
最底层是系统硬件。上面是第三方索引库。在最上层,Knowhere通过CGO与索引节点和查询节点交互,CGO允许Go包调用C代码。
Knowhere的优势
以下是Knowhere与Faiss相比的优势。
支持比特视图
Milvus 引入了比特集机制来实现 "软删除"。软删除的向量仍然存在于数据库中,但在向量相似性搜索或查询时不会被计算。
比特集中的每个比特都对应一个索引向量。如果某个向量在比特集中被标记为 "1",则表示该向量已被软删除,在向量搜索过程中不会涉及。比特集参数适用于 Knowhere 中所有公开的 Faiss 索引查询 API,包括 CPU 和 GPU 索引。
有关比特集机制的更多信息,请查看比特集。
支持二进制向量索引的多种相似性度量方法
Knowhere支持Hamming、Jaccard、Tanimoto、Superstructure和Substructure。Jaccard和Tanimoto可用于测量两个样本集之间的相似性,而Superstructure和Substructure可用于测量化学结构的相似性。
支持 AVX512 指令集
除了Faiss已经支持的AArch64、SSE4.2和AVX2指令集外,Knowhere还支持AVX512指令集,与AVX2指令集相比,AVX512指令集可将索引构建和查询性能提高20%至30%。
自动选择SIMD指令
Knowhere支持在任何CPU处理器(本地部署和云平台)上自动调用合适的SIMD指令(如SIMD SSE、AVX、AVX2和AVX512),因此用户无需在编译时手动指定SIMD标志(如"-msse4")。
Knowhere 是通过重构 Faiss 的代码库而构建的。依赖于 SIMD 加速的常用函数(如相似性计算)被分解出来。然后为每个函数实现四个版本(即 SSE、AVX、AVX2 和 AVX512),并将每个版本放入单独的源文件中。然后,使用相应的 SIMD 标志对源文件进行单独编译。因此,在运行时,Knowhere 可以根据当前的 CPU 标志自动选择最合适的 SIMD 指令,然后使用挂钩功能链接正确的函数指针。
其他性能优化措施
阅读《Milvus: A Purpose-Built Vector Data Management System》,了解有关 Knowhere 性能优化的更多信息。
Knowhere 代码结构
Milvus 中的计算主要涉及向量和标量操作。Knowhere 只处理向量索引的操作符。
索引是一种独立于原始向量数据的数据结构。一般来说,索引需要四个步骤:创建索引、训练数据、插入数据和建立索引。在一些人工智能应用中,数据集训练与向量搜索是分离的。先对数据集的数据进行训练,然后插入到 Milvus 等向量数据库中进行相似性搜索。例如,开放数据集 sift1M 和 sift1B 区分了用于训练的数据和用于测试的数据。
然而,在 Knowhere 中,用于训练的数据和用于搜索的数据是相同的。Knowhere 会对一个数据段中的所有数据进行训练,然后插入所有训练过的数据并为它们建立索引。
DataObj基类
DataObj 是 Knowhere 中所有数据结构的基类。 是 中唯一的虚拟方法。Index 类继承自 ,其字段名为 "size_"。Index 类还有两个虚拟方法-- 和 。从 派生的 类是所有向量索引的虚拟基类。 提供的方法包括 , , , 和 。Size() DataObj DataObj Serialize() Load() Index VecIndex VecIndex Train() Query() GetStatistics() ClearStatistics()
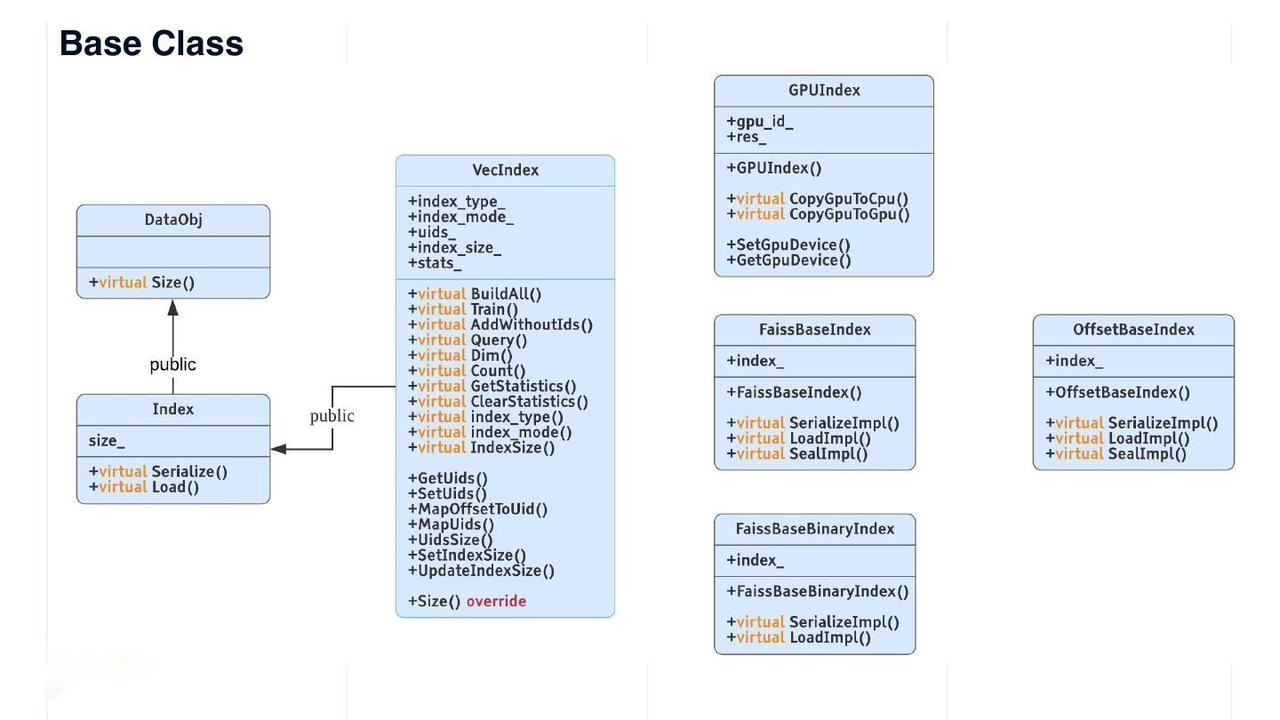 基类
基类
上图右侧列出了其他一些索引类型。
Faiss 索引有两个基类:
FaissBaseIndex用于浮点向量上的所有索引,FaissBaseBinaryIndex用于二进制向量上的所有索引。GPUIndex是所有 Faiss GPU 索引的基类。OffsetBaseIndex是所有自主开发索引的基类。鉴于索引文件中只存储向量 ID,128 维向量的文件大小可减少 2 个数量级。
IDMAP强制搜索
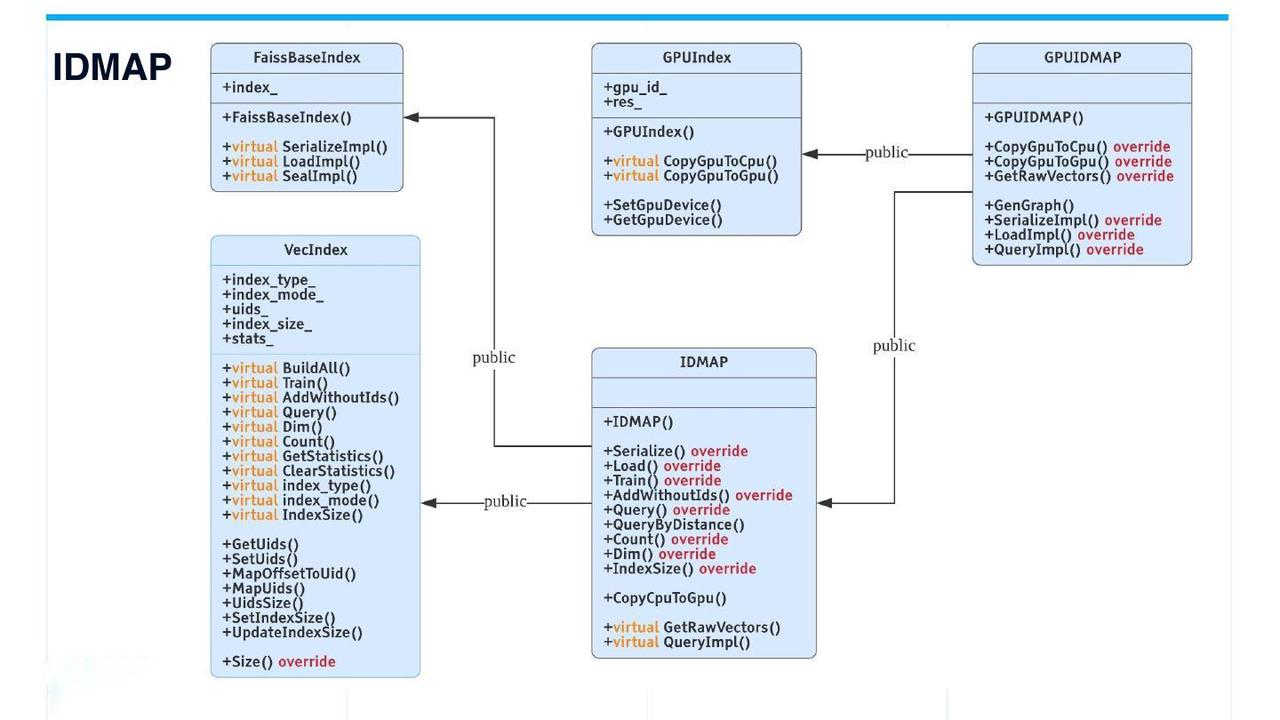 IDMAP
IDMAP
从技术上讲,IDMAP 不是索引,而是用于暴力搜索。向量插入数据库时,既不需要数据训练,也不需要建立索引。搜索将直接在插入的向量数据上进行。
不过,为了保持代码的一致性,IDMAP 也继承自VecIndex 类及其所有虚拟接口。IDMAP 的用法与其他索引相同。
IVF 索引
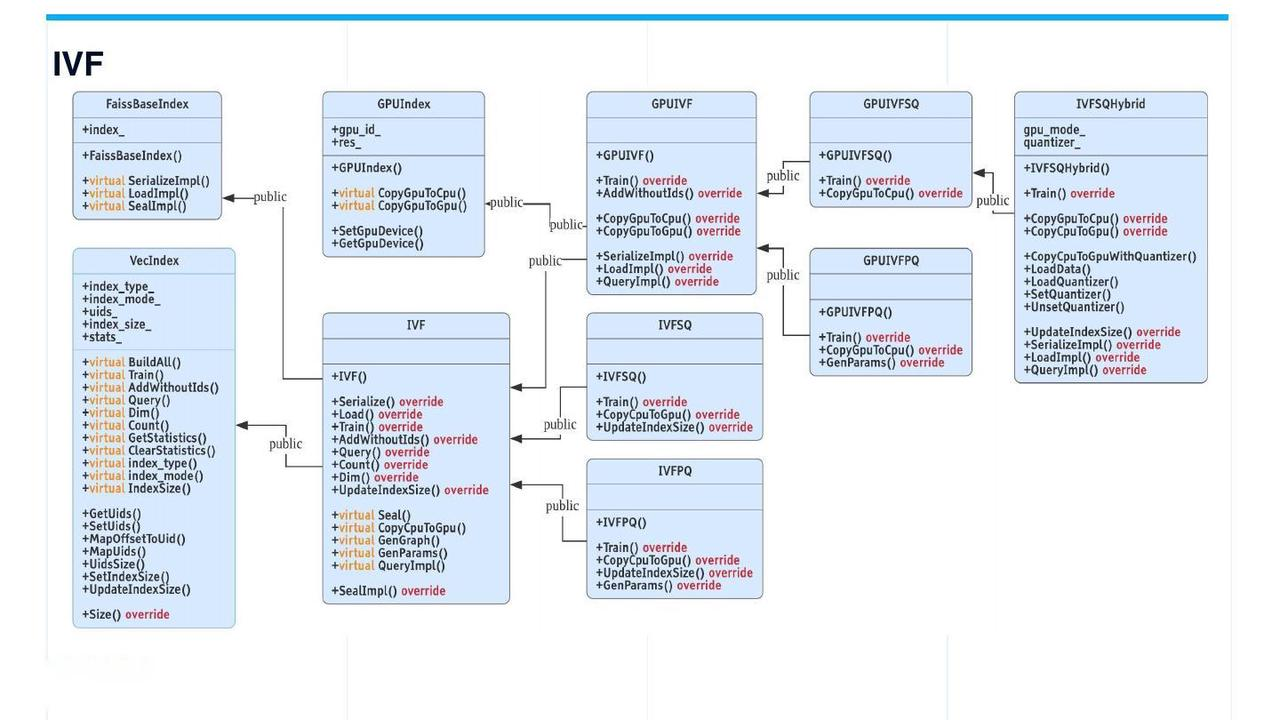 IVF
IVF
IVF(倒置文件)索引是最常用的索引。IVF 类衍生自VecIndex 和FaissBaseIndex ,并进一步扩展到IVFSQ 和IVFPQ 。GPUIVF 衍生自GPUIndex 和IVF 。然后,GPUIVF 进一步扩展到GPUIVFSQ 和GPUIVFPQ 。
IVFSQHybrid 是一个自主开发的混合索引。粗量化器在 GPU 上执行,而桶中的搜索则在 CPU 上进行。 的召回率与 相同,但性能更好。IVFSQHybrid GPUIVFSQ
二进制索引的基类结构相对简单。BinaryIDMAP 和BinaryIVF 由FaissBaseBinaryIndex 和VecIndex 派生而来。
第三方索引
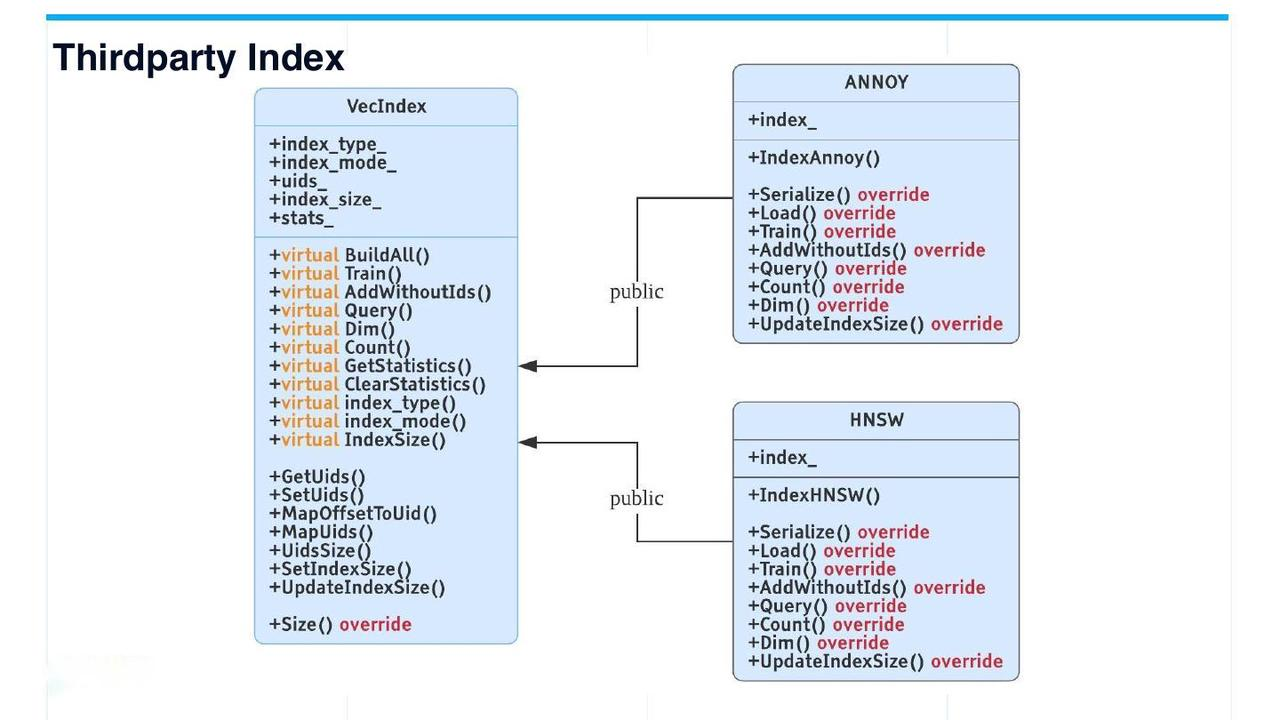 第三方指数
第三方指数
目前,除了 Faiss 之外,只支持两种第三方索引:基于树的索引Annoy 和基于图的索引HNSW 。这两种常用的第三方指数均来自VecIndex 。
向Knowhere添加索引
如果想在Knowhere中添加新的索引,首先可以参考现有的索引:
要添加基于量化的指数,请参考
IVF_FLAT。要添加基于图的索引,请参考
HNSW。要添加基于树的索引,请参阅
Annoy。
参考现有索引后,可以按照以下步骤向Knowhere添加新索引。
在
IndexEnum中添加新索引的名称。数据类型为字符串。在文件
ConfAdapter.cpp中为新索引添加数据验证检查。验证检查主要用于验证数据训练和查询的参数。为新索引创建一个新文件。新索引的基类应包括
VecIndex和VecIndex的必要虚拟接口。在
VecIndexFactory::CreateVecIndex()中添加新索引的索引构建逻辑。在
unittest目录下添加单元测试。
参考文献: https://milvus.io/docs/zh/architecture_overview.md